Information Retrieval (IR) Nedir? SEO için Neden Önemlidir ?
Information Retrieval (IR), bilgisayar bilimlerinde belirli bir bilgi ihtiyacına (sorgu – Query) yönelik bir belge koleksiyonu içerisinde bilgi arama sürecine verilen isimdir.
Information Retrieval (bilginin edinilmesi – bilgi çekme) sürecinde, talep edilen bilgi ile uyumlu veri, yapılandırılmamış veri kaynaklarından çeşitli arama teknik ve metotları uygulanarak edilinir. Talep edilen bilgi ile alakalı verinin, yapılandırılmamış veri kaynaklarında bulunması information retrieval sürecinin temelini oluşturur. Bu nedenle information retrieval işlemi, arama motorlarının temel işlevlerinden biridir.
Günümüzde klasik anlamda sıklıkla bilgi arama gerçekleştiren araştırmacılar, kütüphaneciler ve bilim insanlarının dışında arama motorlarında gündelik arama gerçekleştiren kullanıcıların her biri de arama motorlarına gönderdikleri sorgular (queries) ile bir information retrieval sürecine dahil olurlar. Arama motorları kullanıcılardan gelen ve geleceğini tahmin ettikleri sorgulara yönelik information retrieval süreçleri gerçekleştirerek kullanıcıların sorguları vasıtasıyla ilettikleri bilgi taleplerini, doğru veriler ile eşleştirirler.
Information Retrieval sürecinde klasik anlamda metin içeren dokümanlardan gerekli bilginin edinilmesi olduğu gibi dijital ortamda bulunan tüm dokümanlardan da bilgi edinme süreci information retrieval’ın bir parçasıdır. Örneğin: veritabanları, resimler, multimedia içerikleri vb.
Information retrieval süreci bilginin edinilmesini kapsadığı gibi edinilen bilginin ihtiyaç duyulması halinde sunulabilmesi için toplanan bilgilerin depolanmasını da kapsar. Information retrieval süreci tarihsel olarak gelişirken bilginin edinilmesi ile alakalı çeşitli teknikler geliştirildiği gibi edinilen bilgilerin kategorizasyonu, bilgide yanılma payı ve edinilen bilginin depolanması gibi konularda da çok ciddi çalışmalar ve ilerlemeler gerçekleştirilmiştir.
Günümüzde Google gibi gelişmiş arama motorları elde ettikleri büyük ve başarılı bilgi edinme tekniklerinin yanı sıra edinilen bilginin doğrulunun kontrol edilmesi, potansiyel bilgi ihtiyaçlarının yorumlama ve tahmin yolu ile belirlenerek giderilmesi gibi alanlarda yoğun çalışmalar gerçekleştirmektedir.
Information Retrieval Ne Demektir ?
Information Retrieval (IR) Türkçede bilgi edinme, bilgi alma demektir. Klasik anlamda information retrieval dendiğinde genel olarak metin dokümanları içerisinden ihtiyaç duyulan bilginin çeşitli methodlar ile edinilmesi kast edilmektedir.
Information Retrieval’ın Tarihi
İhtiyaç duyulan herhangi bir bilgi ile alakalı veri toplama sürecinde bilgisayarların kullanılması fikri ilk defa Vannevar Bush tarafından 1945 yılında As We May Think isimli makalede ortaya atılmıştır. (Kaynak: http://singhal.info/ieee2001.pdf). İhtiyaç duyulan bilgiyi arayan bir bilgisayarın tanımlaması ise ilk defa 1948 yılında Holmstrom tarafından yapılmıştır. Ortaya atılan fikirler sonrası otomatik bir şekilde çalışan bir bilgi edinme sistemi ilk defa 1950’li yıllarda duyurulmuştur.
1960’larda ilk defa büyük bir information retrieval grubu Cornell’da Gerard Salton tarafından kurulmuştur.
1970 lere gelindiğinde bir kaç information retrieval tekniğinin görece küçük bilgi edinme kaynaklarında gayet güzel performans gösterdiği yapılan testlerde ortaya konmuştur.
1989 yılında Tim Berners Lee tarafından duyurulan buluş, World Wide Web (WWW) günümüzün web tabanlı information retrieval sürecinin temelini oluşturur ve bulunduğu dönemde bilginin depolanması, bilginin erişilmesi gibi konulara olan bakış açısını devrimsel nitelikte değiştirmiştir.
WWW (World Wide Web) ile bir ağ üzerinde çeşitli verileri barındıran dokümanların (web sayfalarının) hiper metinler aracılığı ile birbirine bağlanması ve bu bağlanan metinlerin bilgi ihtiyacına göre edinilmesi web tabanlı information retrieval’ın temel taşlarından biridir.
1990’lı yıllara gelindiğinde, 1992 yılında Amerikan Savunma Bakanlığı ve Ulusal Standartlar ve Teknoloji Enstitüsü (NIST), Text Retrieval Conference’a (TREC – Metin Alma Konferansı) sponsor olarak information retrieval ile alakalı gerçekleştirilen çalışmaların çok daha hızlanmasına katkı sağlamıştır.
Modern arama motorlarının ortaya çıkışı ile birlikte web tabanlı büyük dokümanlar üzerinden ihtiyaç duyulan bilgilerin edinilmesi ve işlenmesine yönelik ihtiyaç artış göstermiş ve bu alanda gerçekleştirilen çalışmalar hızlanmıştır.
Information Retrieval Modelleri
Information Retrieval (IR) modelleri, kullanıcı tarafından iletilen sorgu (bilgi ihtiyacına) yönelik dokümanları belirlemekte, bilginin edinilmesinde ve kaynakların sıralanmasında kullanılır. En temel (basic) information retrieval modelleri 3’e ayrılır.
Bunlar ;
- Boolean Model
- Vector Space Model
- Probabilistic Model
1 – Boolean Model
Boolean modeli, sorgunun işlenmesi ve sıralanması için küme teorisini, yani Boolean cebrini ve onun üç bileşeni olan Ve (AND), Veya (OR) ve Yok’u (NOT) kullanır. Booelan Model ile alakalı en önemli dezavantaj; sorgu ile alakalı bulunan ve eşleştirilen belgelerin sıralanamamasıdır.
“Boolean modelinde, tüm belgeler bir dizi farklı kelime veya anahtar kelime ile ilişkilendirilir ve Kullanıcı Sorguları ayrıca Ve, Veya, Veya Yok ile ayrılmış anahtar kelime ifadeleriyle temsil edilir.” Bu nedenle Boolean modelde bir kaynak bir sorgu ile ilişkili yada ilişkisizdir. Ortada bir skor yada yakınlık ile ilgili bir alaka skoru hesaplaması yoktur.
2 – Vector Space Model
Vector Space (Vektör Space Model) modeli belgeleri kullanıcı sorgusu ile ilişkilendirir ve aralarındaki benzerliğe göre dokümanları skorlandırıp sıralar. Vector Space modelinde kullanıcı sorguları ve belgeler birer vector olarak numaralandırılır ve vektörler arasındaki benzerlik değeri özel bir fonksiyon kullanılarak hesaplanır.
Vektör Space Modeli ile tf-idf ağırlıklandırma olarak da bilinen terim’in sayfa içerisindeki kullanım yoğunluğuna göre terime bir ağırlık değeri atama şeması uygulanmaktadır.
3 – Probabilistic Model (Olasılıksal Model)
Olasılıksal modelin (probabilistic model) en önemli ve temel işlevi, bir kullanıcının sorgusuna karşılık belirlenen belgeleri alaka (yakınlık) olasılıklarına göre sıralamaya başlamasıdır.
Probabilistic modelde kullanıcı sorgusu da sorguya karşılık gelen dokümanlarda ikili vectorler (ikili sayısal değerler) ile gösterilir {0,1 & 1,0 gibi} ve her ikili vektör bileşeni, belgede veya sorguda belirli bir belge bileşeni veya terimi olup olmadığını gösterir.
Dizindeki tüm dokümanların bir alt kümesi olarak alakalı dokümanların vektör değeri, alakasız dokümanların tüm indeks dokümanlarının bir alt kümesi olarak vektör değeri, kullanıcıdan gelen o an ki sorgunun dizindeki tüm indeks terimlerinin bir alt kümesi olarak vektör değeri gibi binary değerler özel olasılık fonksiyonları ile kullanılarak bir dokümanın sorguya olan yakınlığı hesaplanır ve çıkan sonuca göre dokümanların sorguya özel sıralaması sağlanır.
Sorguya uzak olan dokümanların binary (ikili) vektör değerleri de hesaplamalarda kullanılır.
Web Tabanlı Information Retrieval
Web tabanlı information retrieval, internet (ağ) üzerinde yer alan çok sayıda büyük ve küçük ölçekli döküman koleksiyonundan bilgi edinmeye verilen isimdir.Günümüz arama motorlarının temel işlevlerinden olan web corpus (internet ağı içerisindeki dokümanlar) içerisinden bilgi edinme tam olarak web information retrieval olarak adlandırılır.
Web tabanlı information retrieval da klasik information retrieval metodları uygulanabilir ancak klasik information retrieval dokümanlarından farklı ihtiyaçları sebebiyle web tabanlı information retrieval da daha özel metodlar uygulanmaktadır.
Genel olarak web information retrieval, belgelerin metinsel içeriğinden ve web’in dağınık yapısından bilgi toplama, ayrıca kullanıcıların arama davranışından ve Web ortamında elde edilen kullanıcı geri bildirim datalarının değerlendirilmesi ile ilgilenir. Web (internet) information retrieval, bilgi edinmenin yanı sıra kullanıcıdan gelen sorgulara karşılık gelen, bilgi edinilen dokümanların sıralanmasında gerekli olan metrikleri de inceler. Örneğin: linkler, dokümanların yapısı, dökümanın sorgu alakası, dokümanın kalitesi vb.
Arama motorları tarafından gerçekleştirilen information retrieval süreci tipik bir web tabanlı information retrieval sürecidir. Arama motorlarına girilen sorgulara karşılık gelen cevapların toplanması ve sıralanması süreci web tabanlı information retrieval olarak adlandırılır.
Web Tabanlı Information Retrieval vs Klasik Information Retrieval
Web tabanlı information retrieval, internet ağı üzerinde yer alan çok geniş sayıda yapılandırılmamış doküman koleksiyonundan bilgi toplamaya ve toplanan bilgiyi ve kaynağını değerlendirmeye odaklanırken klasik information retrieval görece daha küçük, daha kontrollü ve çok daha düzenli bilgi kaynaklarından bilgi toplamaya odaklanır.
Web tabanlı information retrieval da incelenen kaynakla hiper metinler (hyperlink) yolu ile birbirine bağlanırken klasik information retrieval da kullanılan kaynaklarda bu durum geçerli değildir.
Geleneksel, linkler yolu ile birbirine bağlı olmayan information retrieval süreci ve kaynakları, web tabanlı information retrieval süreç ve kaynaklarından eskidir ve halen varlığını sürdürmektedir. Bir üniversitenin kütüphanesinde fiziksel gerçekleştirilen bilgi araması, fiziksel ve düzenli bir doküman içerisinde gerçekleştirilen bir bilgi araması geleneksel information retrieval sürecine örnektir.
Geleneksel information retrieval kaynakları genellikle statik, belirli bir yapı ve düzen dahilinde kategorize edilmiş kaynaklardır.
Günümüzde gelişen arama motoru teknolojileri ve internet kullanımına bağlı olarak web tabanlı information retrieval’ın yoğunluğu ve önemi artmıştır. Web tabanlı information retrieval sürecinde, belirli bir düzen ve kural dahilinde kategorize edilmemiş kaynaklar ve dokümanlardan düzensiz olarak eklenmiş bilgiler edinilir. Edinilen bilginin doğruluğunun kontrolünde farklı method ve teknolojiler geliştirilmiştir.
Google gibi gelişmiş arama motorları günde aldıkları milyarlarca kullanıcı sorgusunu, web de yer alan düzensiz dokümanlardaki bilgiler ile eşleştirerek kullanıcı ihtiyaçlarına cevap verirler. Web de yer alan dokümanlar belirli bir bilgi barındırma method ve yapısı içerisinde oluşturulmadıkları için Google gibi gelişmiş arama motorları ihtiyaç duydukları net bilgileri kazıyabilmek için çeşitli information retrieval metodları geliştirmişlerdir. (Örn: Passage (Pasaj) indexing)
Information Retrieval Nasıl Çalışır?
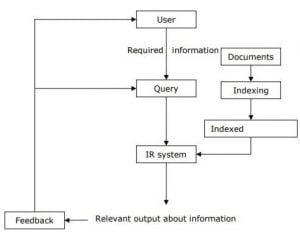
Bir information retrieval süreci, kullanıcıdan alınan bir bilgi ihtiyacına yönelik sorgu ile başlar, günümüzde kullanılan bütün gelişmiş arama motorları gelen sorguları cevaplayabilmek için web tabanlı information retrieval uygular.
Sorgular (Queries), web tabanlı information retrieval sürecinde kullanıcının ihtiyaç duyduğu bilgi ihtiyacının string (metinsel) halidir. Information retrieval sürecinde bir sorgu, koleksiyondaki tek bir nesneyi benzersiz şekilde tanımlamaz. Bir sorgu ile alakalı, ilişkilendirilebilecek binlerce yada milyarlarca farklı tip ve kategoride kaynak olabilir.
Bu noktada arama motorları, web tabanlı information retrieval sürecinde sorguyu işlerken ve bu sorgu ile alakalı kaynakları ilişkilendirip sıralandırırken, kaynakların doğruluğu ve güvenilirliğine ekstra önem göstermek durumundadır. Çünkü kullanıcı ihtiyacının doğru karşılanabilmesi için web de yer alan milyarlarca kaynak ve bu kaynaklarda yer alan milyarlarca (trilyonlarca) bilgi doğru olarak edinilmeli ve sorgular doğru kaynaklar ile eşleştirilmelidir.
Kullanıcı tarafından arama motoruna bir sorgu gönderildiğinde, arama motoru dizininde (index) barındırdığı sorgu ile alakalı ve sıralandırılmış kaynakları arama sonuçlarında (SERP) kullanıcıya gösterir. Kullanıcı ihtiyacı dahilinde uyumlu gördüğü kaynaklardan herhangi bir veya birkaç tanesini seçerek süreci devam ettirir yada aramayı sonlandırır.
Web tabanlı information retrieval sürecinde kullanıcıdan eşleştirmesi çok zor, spesifik bir sorgu geldiğinde sorgu ile birebir eşleşen kaynaklar bulunmasa dahi arama motorları sorgu ile olan alaka skoruna göre farklı kaynakları sıralandırıp kullanıcıya sunabilir.
Information Retrieval SEO için Neden Önemlidir?
Bütün arama motorları web de yapılandırılmamış kaynaklarda bulunan, kullanıcının ihtiyaç duyduğu verileri toplamak için information retrieval gerçekleştirir. Arama motorları kullanıcının ihtiyacını maksimum başarı (memnuniyet) ile karşılayabilmek için gelişmiş information retrieval ve sıralama algoritmaları (örn: pagerank) kullanarak en iyi sonuçları elde etmeyi amaçlar.
SEO noktasında web sitelerinin, arama motorlarının (arama motoru botlarının – Örn: Google bot) information retrieval sürecini kolaylaştıracak şekilde kaynaklarını optimize etmesi, arama motoru botlarının doğru bilgiyi çok daha doğru ve kolay şekilde kaynaktan toplaması ve buna bağlı olarak web sitesini arama sonuçlarında ödüllendirmesi ile sonuçlanır.
Yapılandırılmış verilerin kullanımı (schema markups), semantic (anlamsal) HTML etiketlemelerinin kullanılması, resim alt etiketleri, hiyerarşik başlık yapısı gibi anlamsal SEO iyileştirmeleri, information retrieval sürecinde arama motorlarının doğru veriyi kaynaktan edinmesini kolaylaştıracağından ilgili iyileştirmeler hem arama motoru hem de web sitesi için faydalıdır ve önemlidir.



